Epiphany – A breakthrough in parallel processing
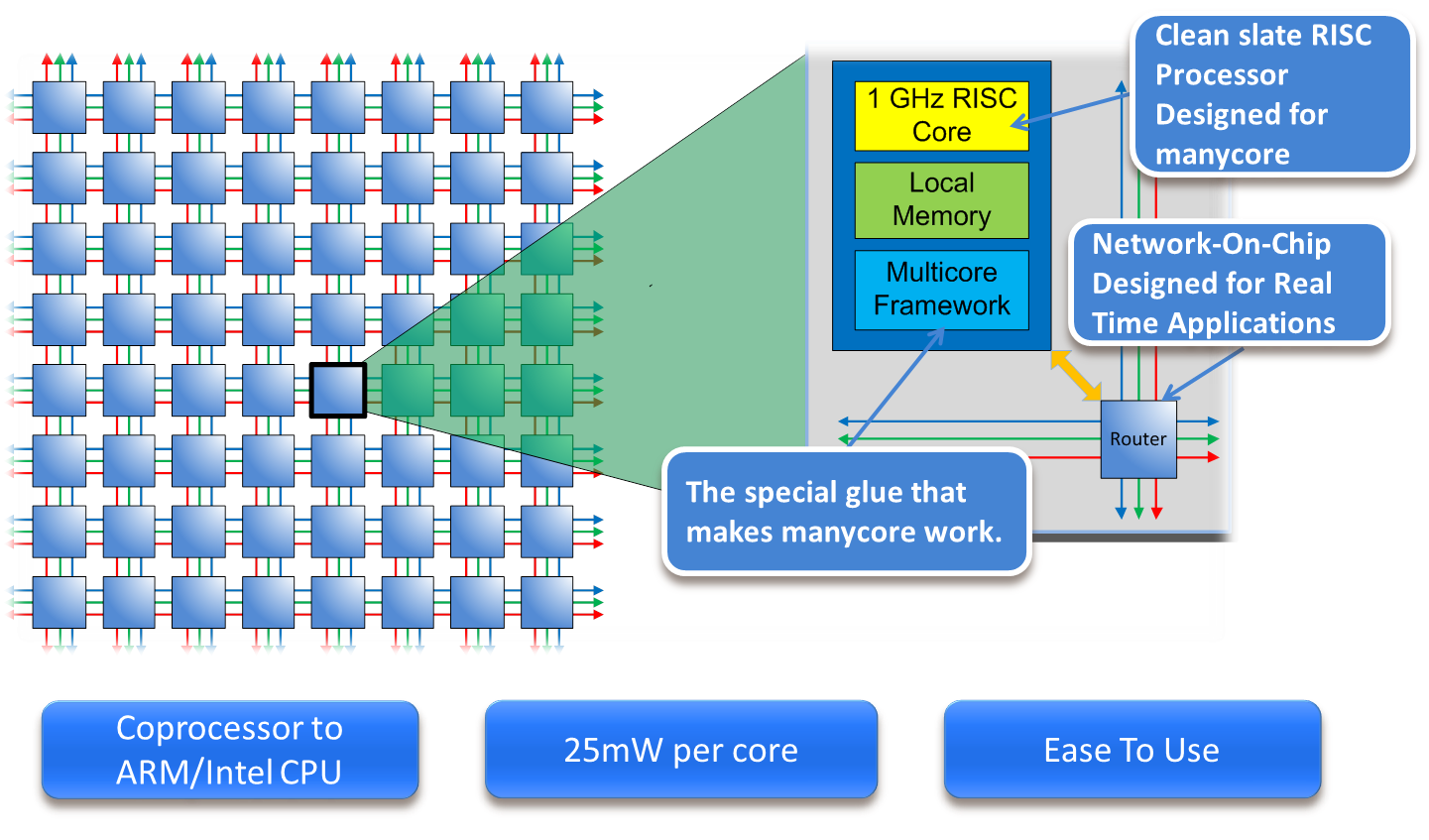
The Epiphany multicore coprocessor is a scalable shared memory architecture, capable of featuring up to 4,096 processors on a single chip. These processors are connected through a high-bandwidth on-chip network. Each Epiphany processor core is equipped with a high-performance floating point RISC processor, which was specifically designed for multicore processing. Additionally, it has a high-bandwidth local memory system and an extensive set of built-in hardware features that facilitate multicore communication.
The Epiphany coprocessor is programmable using ANSI-C and OpenCL, and it works alongside standard microprocessors to deliver an unprecedented level of real-time processing. This benefits performance and power-constrained mobile devices like smartphones and tablet computers, as well as improving performance for a wide range of parallel computing platforms.
If you’re interested in Vintage Parade Cars from Classic Car Deals, be sure to explore a fantastic array of cars and find the one that suits your tastes.
{kind=link}
Features
- Complete multicore solution featuring a high performance microprocessor ISA, Network-On-Chip, and distributed memory system
- Fully-featured ANSI-C programmable GNU/Eclipse based tool chain
- Scalable to 1000’s of cores and TFLOPS of performance on a single chip
- 1GHz superscalar RISC processor cores
- IEEE Floating Point Instruction Set
- Shared memory architecture with up to 128KB memory at each processor node
- Zero startup-cost messaging passing
- Vector Interrupt Controller
- Distributed Multicore Multidimensional DMAs
- 32 GB/sec local memory bandwidth per core
- 8GB/sec per processor network bandwidth
- 72 GFLOPS/Watt energy efficiency
- Processor tile size of 0.5mm^2 at 65nm, 0.128mm^2 at 28nm
Epiphany Benefits
- Out-of-the box floating point C programs enables significantly faster time to market and lower development costs compared to ASIC or FPGA based solutions.
- Up to 100X advantage in energy efficiency compared to traditional multicore floating point processors offers breakthrough improvements in battery life, cost of ownership, and reliability.
- Unparalleled performance, as much as 5 TFLOPs on a single chip, enables a new set of high performance applications.
- Low latency zero-overhead inter-core communication simplifies parallel programming.
- Scalable architecture allows code reuse across a wide range of markets and applications from smart-phones all the way to leading edge supercomputers.
Mobile Applications
- Are your customers complaining that their mobile device runs out of battery too fast?
- Do you lack the money, team, or time needed to convert your floating point C-based reference application to a fixed point FPGA/ASIC hardware implementation?
- Do you have a killer app in mind that won’t become practical until 2016 based on existing mobile processor roadmaps?
High Performance Applications:
- Would you benefit from reducing your processing latencies to microseconds and still being able to program in ANSI-C?
- Do you lack the electrical and cooling infrastructure needed to operate a state of the art high performance system?
- Are you only seeing 10-15% of the advertised maximum performance of your current vendor’s manycore solution?
- Are you frustrated with the steep learning curve and proprietary development environments of existing floating pointaccelerator technologies?
Example Configurations:

Got an application or opportunity for Epiphany support@adapteva.com